Maintaining a fully functional Drupal 7 site and keeping it updated with security updates year-round takes a lot of work and time. For example, some sites are only active during certain times of the year, so continuously upgrading to new Drupal versions doesn't always make the most sense. If a site is updated infrequently, it's often an ideal candidate for a static site.
To serve static pages, GitHub Pages is a good, free option, especially when already using GitHub. GitHub Pages deploys Jekyll sites, but Jekyll is perfectly happy to serve up static HTML, which doesn't require any actions other than creating functional HTML pages to get a solution working. Using this fishing tournament website as the basis for this article, here’s how to retire a Drupal site using HTTrack.
Inactivate the Site
To get started, create a local copy of the original Drupal site and prepare it to go static using ideas from Sending A Drupal Site into Retirement.
Create GitHub Page
Next, create a project on GitHub for the static site and set it up to use GitHub Pages. Just follow the instructions to create a simple Hello World repository to be sure it’s working. It’s a matter of choosing the option to use GitHub Pages in the settings and identifying the GitHub Pages branch to use. The GitHub pages options are way down at the bottom of the settings page. There's an option to select a GitHub theme, but if there's one provided in the static pages, it will override anything chosen. So, really, any theme will do.
A committed index.html file echoes back "Hello World" and the new page becomes viewable at the GitHub Pages URL. The URL pattern is http://REPO_OWNER.github.io/REPO_NAME; the GitHub Pages information block in the repository settings will display the actual URL for the project.
Create Static Pages with HTTrack
Now that there's a place for the static site, it's time to generate the static site pages into the new repository. Wget could spider the site, but a preferred solution is one that uses HTTrack to create static pages. This is a tool that starts on a given page, generally the home page, then follows every link to create a static HTML representation of each page that it finds. This will only be sufficient if every page on the site is accessible from another link on the site and the navigation or other links on the home page. HTTrack won't know anything about unlinked pages, although there are ways to customize the instructions to identify additional URLs to spider.
Since this solution doesn’t rely on Drupal at all, it's possible to use it for a site built with any version of Drupal, or even sites built with other CMSes. It self-discovers site pages, so there's no need to provide any manifest of pages to create. HTTrack has to touch every page and retrieve all the assets on each page, so it can be slow to run, especially when running it over the Internet. It's best to run it on a local copy of the site.
It's now time to review all the link elements in the head of the pages and make sure they are all intentional. Using the Pathauto module, the head elements added by Drupal 7, such as <link rel="shortlink" href="/node/9999" />, should be removed. They point to URLs that don't require replication in the static site, and HTTrack will try to create all those additional pages when it encounters those links.
When using the Metatags module, configuring it to remove those tags is possible. Instead, a bit of code like the following is used in a custom module to strip tags out (borrowed from the Metatags module, code appropriate for a Drupal 7 site):
/**
* Implements hook_html_head_alter().
*
* Hide links added by core that we don't want in the static site.
*/
function MYMODULE_html_head_alter(&$elements) {
$core_tags = array(
'generator',
'shortlink',
'shortcut icon',
);
foreach ($elements as $name => &$element) {
foreach ($core_tags as $tag) {
if (!empty($element['#attributes']['rel']) && $element['#attributes']['rel'] == $tag) {
unset($elements[$name]);
}
elseif (!empty($element['#attributes']['name']) && strtolower($element['#attributes']['name']) == $tag) {
unset($elements[$name]);
}
}
}
}
The easiest way to install HTTrack on a Mac is with Homebrew:
brew install httrack
Based on the documentation and further thought, it became clear that the following command string is the ideal way to use HTTrack. After moving into the local GitHub Pages repo, the following command should be executed where LOCALSITE is the path to the local site copy that's being spidering, and DESTINATION is the path to the directory where the static pages should go:
httrack http://LOCALSITE -O DESTINATION -N "%h%p/%n/index%[page].%t" -WqQ%v --robots=0 --footer ''
The -N flag in the command will rewrite the pages of the site, including pager pages, into the pattern /results/index.html. Without the -N flag, the page at /results would have been transformed into a file called results.html. This will take advantage of the GitHub Pages server configuration, which will automatically redirect internal links that point to /results to the generated file /results/results.html.
The --footer '' option means omit comments that HTTrack automatically adds to each page and looks like the following. This gets rid of the first comment, but nothing appears to get rid of the second one. Getting rid of the first one, which has a date in it, eliminates having a Git repository in which every page appears to change every time HTTrack runs. It also obscures the URL of the original site, which may be confusing since it's a local environment.
<!-- Mirrored from everbloom-7.lndo.site/fisherman/aaron-davitt by HTTrack Website Copier/3.x [XR&CO'2014], Sun, 05 Jan 2020 10:35:55 GMT -->
<!-- Added by HTTrack --><meta http-equiv="content-type" content="text/html;charset=utf-8" /><!-- /Added by HTTrack -->
The pattern also deals with paged views results. It tells HTTrack to find a value in the query string called "page" and inserts that value, if it exists, into the URL pattern in the spot marked by [page]. Paged views create links like /about/index2.html, /about/index3.html for each page of the view. Without specifying this, the pager links would be created as meaningless hash values of the query string. This way, the pager links are user-friendly and similar (but not quite the same) as the original link URLs.
Shortly after the process starts, it will stop and ask a question about how far to go in the following links. '*' is the response to that question:
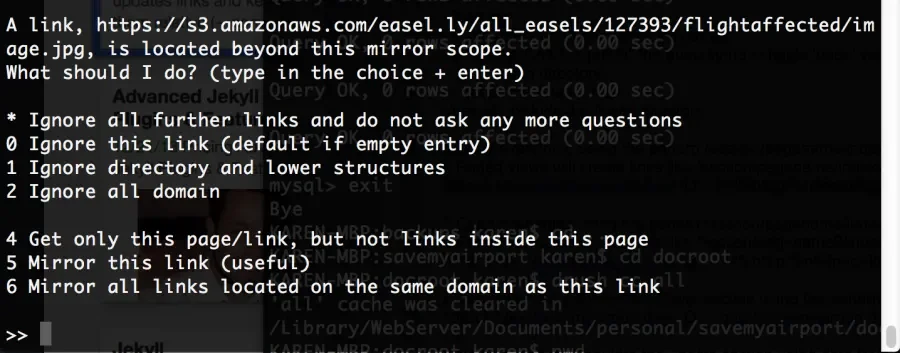
The progress is viewable as it goes to see which sections of the site it is navigating into. The '%v' flag in the command tells it to use verbose output.
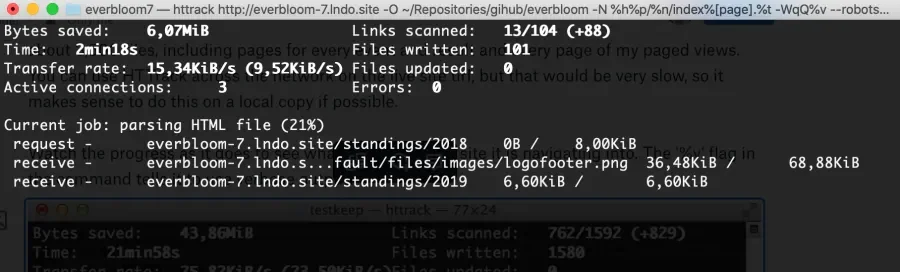
HTTrack runs on a local version of the site to spider and creates about 3,500 files, including pages for every event and result and every page of the paged views. HTTrack is to slow to use across the network on the live site URL, so it makes sense to do this on a local copy. The first attempt took nearly two hours because so many unnecessary files were created, such as an extra /node/9999.html file for every node in addition to the desired file at the aliased path. After a while, it was apparent they came from the shortlink in the header pointing to the system URL. Removing the short links, cut the spidering time by more than half. Invalid links and images in the body of some older content that HTTrack attempted to follow (creating 404 pages at each of those destinations) also contributed to the slowness. Cleaning up all of those invalid links caused the time to spider the site to drop to less than a half-hour.
The files created by HTTrack are then committed to the appropriate branch of the repository, and in a few minutes, the results appear at http://karens.github.io/everbloom.
Although incoming links to /results now work while internal links still look like this in the HTML:
/results/index.html
A quick command line fix to clean that up is to run this, from the top of the directory that contains the static files:
find . -name "*.html" -type f -print0 | xargs -0 perl -i -pe "s/\/index.html/\//g"
That will change all the internal links in those 3,500 pages from results/index.html to /results/ resulting in a static site that pretty closely mirrors the original file structure and URL pattern of the original site.
One more change is to fix index.html at the root of the site. When HTTrack generates the site, it creates an index.html page that redirects to another page, /index/index.html. To clean things up a bit and remove the redirect, I copy /index/index.html to /index.html. The relative links in that file now need to be fixed to work in the new location, so I do a find and replace on the source of that file to remove ../ in the paths in that page to change URLs like ../sites/default/files/image.jpg to sites/default/files/image.jpg.
Once this is working successfully, the final step was to have the old domain name redirect to the new GitHub Pages site. GitHub provides instructions about how to do that.
Updating the Site
Making future changes requires updating the local site and then regenerating the static pages using the method above. Since Drupal is not publicly available, there's no need to update or maintain it, nor worry about security updates, as long as it works well enough to regenerate the static site when necessary. When making changes locally, regenerate the static pages using HTTrack and push up the changes.
The next article in this series will investigate whether or not there is a faster way of creating a static site.